# 高效办公
# potplayer 播放时, 声音有回音
💡:在播放器中点击右键, 选择[声音]=>[声音处理]=>[晶化], 取消[晶化]效果即可.
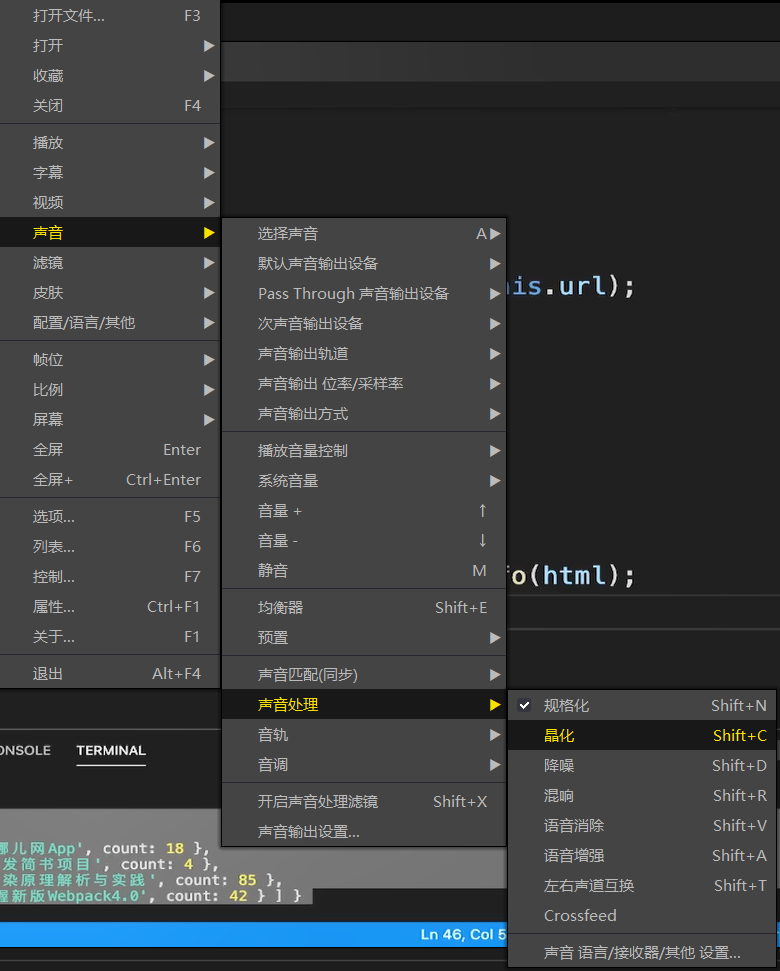
# Windows 添加自定义右键菜单
# 打开注册表
windows键 + R打开运行窗口,输入regedit ,然后点击“确定”打开注册表。
# 找到 shell,然后新建项
依次展开\HKEY_CLASSES_ROOT\*\shell,在shell上点击右键->新建->项,命名为相关库名,例如Decode(最好为全英文),在Decode上点击右键->新建->项,命名为command。
右键命令主要展示名称、展示图标和相关命令三部分构成,这三部分都需要在注册表中进行定义,其中展示名称、展示图标都在Decode中进行定义,其中(默认)中定义展示名称,新建项Icon定义图标路径,而在Decode\command的(默认)中定义打开命令。
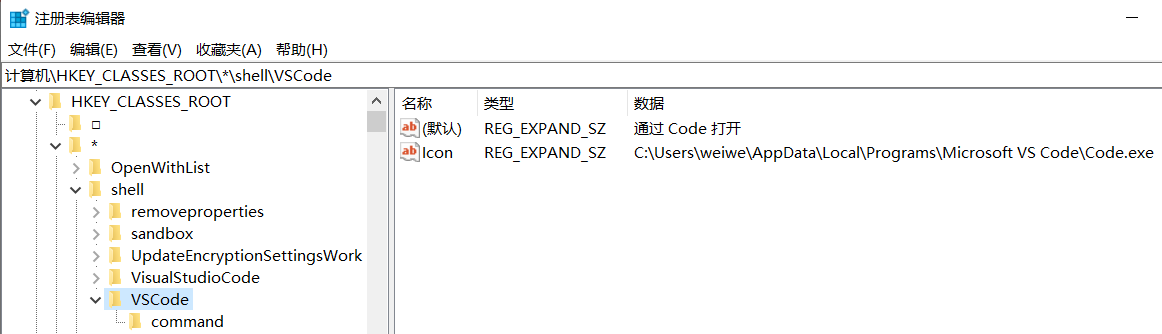
例如,VScode 的右键命令设置的注册表位置为计算机\HKEY_CLASSES_ROOT\*\shell\VSCode,相关设置内容为:
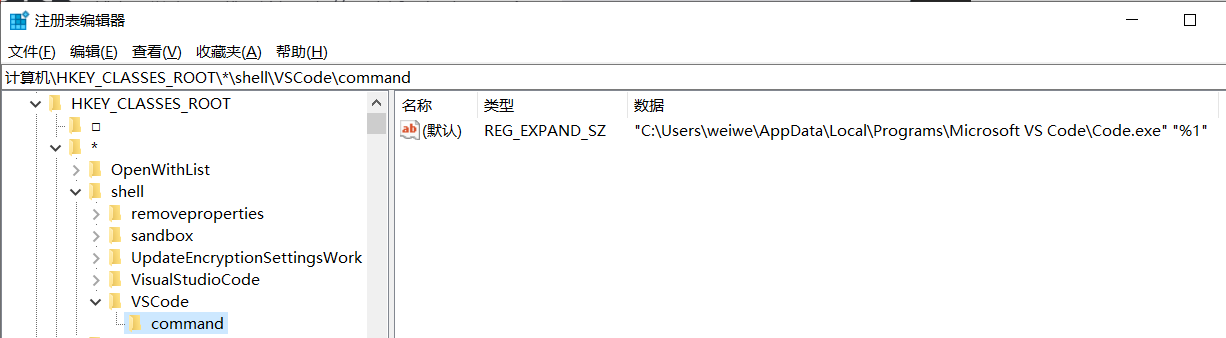
展示名称:通过 Code 打开展示图标:C:\Users\weiwe\AppData\Local\Programs\Microsoft VS Code\Code.exe相关命令:"C:\Users\weiwe\AppData\Local\Programs\Microsoft VS Code\Code.exe" "%1"
名称和图标的设置如下:
命令的设置项如下:
注意
- 注册表项不区分大小写,项目名称
Icon和icon没有区别。 - Icon 的数据项可以是
.exe结尾。 - 设置内容的数据类型都是
字符串型(Reg_SZ)。 - 网上关于命令使用的值基本都没有加引号,但是建议像 VScode 一样把引号加上,尤其是
%1的引号,否则目录有空格就会出问题。
# 一次批量启动多个程序
- 使用批处理命令:
start /d "程序所在路径" 程序名称.exe,启动对应的软件。 - 新建
bat文件,写多条语句,同时启动多个程序
:: 启动复制翻译软件
start /d "C:\Users\weiwe\AppData\Local\Programs\copytranslator\" copytranslator.exe
:: 启动VScode
start /d "C:\Users\weiwe\AppData\Local\Programs\Microsoft VS Code\" Code.exe
:: 启动pdf阅读器
start /d "D:\Program Files (x86)\Zeon\Gaaiho\Gaaiho Reader\bin\" GaaihoReader.exe
:: 启动词典软件
start /d "D:\Program Files\MDictPC\" MDict.exe
3.双击该bat文件,即可批量启动多个程序。
4.也可以使用批处理命令判断程序是否已经运行,例如判断vscode是否运行的代码如下:
tasklist /nh|find /i "Code.exe"
if ERRORLEVEL 1 (echo Code.exe not exist) else (echo Code.exe exists)
因此,可以修改bat文件,使得它先判断该组程序是否运行,如果没有运行则进行运行。含有4个程序的示例代码如下:
%echo off
:: 启动复制翻译软件
tasklist /nh|find /i "copytranslator.exe"
if ERRORLEVEL 1 (start /d "C:\Users\weiwe\AppData\Local\Programs\copytranslator\" copytranslator.exe) else (echo copytranslator.exe exist)
:: 启动VScode
tasklist /nh|find /i "Code.exe"
if ERRORLEVEL 1 (start /d "C:\Users\weiwe\AppData\Local\Programs\Microsoft VS Code\" Code.exe) else (echo Code.exe exist)
:: 启动pdf阅读器
tasklist /nh|find /i "GaaihoReader.exe"
if ERRORLEVEL 1 (start /d "D:\Program Files (x86)\Zeon\Gaaiho\Gaaiho Reader\bin\" GaaihoReader.exe) else (echo GaaihoReader.exe exist)
:: 启动词典软件
tasklist /nh|find /i "MDict.exe"
if ERRORLEVEL 1 (start /d "D:\Program Files\MDictPC\" MDict.exe) else (echo MDict.exe exist)
pause
# windows保存窗口布局
下载windows布局管理器(Windows Layout Manager (opens new window)),解压后运行即可。
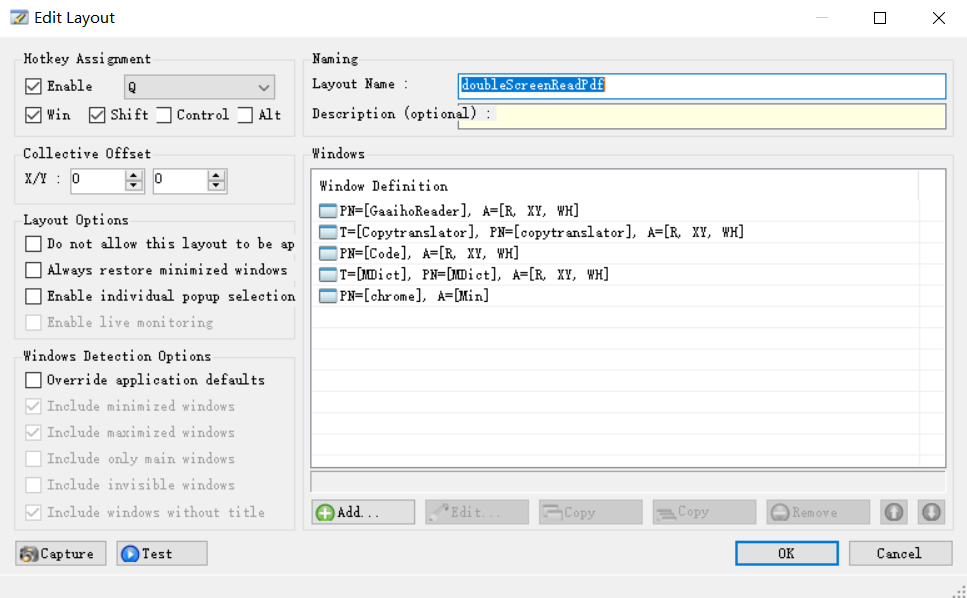
1. 捕获布局,进入软件之后,使用capture按钮可以捕获当前布局,然后删除不需要布局的软件,如下图所示。
2. 修改布局,默认的布局文件会使用windows title属性,而一般软件该值一般都是变动的,所以需要把这个选项去掉;另外在actions中,默认是none of above,而我们一般是最小化或者恢复,所以需要修改为restore或者minimize,例如pdf阅读器的位置设置如下:
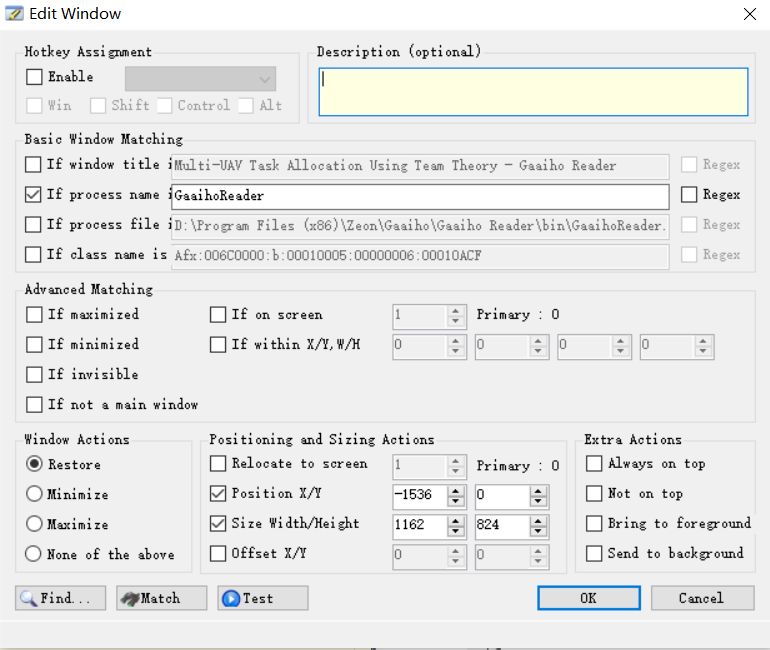
3. 测试布局,使用[test]按钮可以测试刚刚的界面是否达到效果,如果没有问题就可以设置快捷键了。
4. 设置快捷键,我们可以给常用的布局设置快捷键,常用的设置为win+shift+Q,多个布局可以用Q,W,E。
取消恢复对话框
每次调整页面,会弹出确认窗口,如果不需要显示,则可以将其关闭掉,在Options->Configuration中取消Layout Restoration Dialog下面的勾选即可。
# 使用youtube-dl下载网页动画
可以使用youtube-dl (opens new window)下载网页视频,文件可以到蓝奏云下载 (opens new window),下载完成后将解压得到的youtube-dl.exe放到单独的文件夹下,然后在cmd中运行即可,
使用方法很简单,在youtube-dl.exe [视频网址]即可,例如下载【朱一旦】142 一块劳力士的回家路 (opens new window),则使用下面的命令
.\youtube-dl.exe https://www.bilibili.com/video/BV1P7411V7Ga
此时会显示下载情况:

youtube-dl的其他常用命令还有:
[url] 下载对应url的视频
-o '名称' [url] 指定视频下载之后的名称
-h, --help 打印此帮助文本并退出
--version 打印程序版本并退出
-U, --update 将此程序更新为最新版本。
--list-extractors 列出所有支持的提取器
-F [url] 查看目标网址的视频版本
[url1] [url2] [url3] 一次下载多个不同的视频,用空格将多个URL分隔开
--format mp4 [url] 下载mp4格式视频(如果可用)
# 如何快速搜索信息
# site:搜索结果限定在某个网站中
我们经常需要把搜索的范围限定在某个特定的网站中,如果你已经知道某个网站中有自己需要的东西,那么在搜索的时候就可以把搜索范围限定在这个网站中,大大提升查询的效率,方法就是使用site搜索指令。搜索指令site的具体用法就是:关键词+空格+site+英文冒号+搜索范围所限定的网站。
实例,新能源汽车 site:zhihu.com表示知乎网站中搜索关于新能源汽车的信息。
注意
网站前不用加http或者www。比如timepill.net。
# filetype:搜索结果限定为某种文件类型
filetype这个命令在搜索专业文档资料时是非常好用的。具体用法就是:关键词+空格+filetype+英文冒号+文件格式。其中,文件格式可以填写pdf、ppt、doc、jpg等。
实例,2018年考研英语真题 filetype:pdf表示搜索2018年考研英语真题的pdf文档。
# “时间1..时间2”:限定搜索结果的时间范围
“时间1..时间2”这个搜索指令也非常重要,适用于某个特定时间范围内,关于某个关键词的信息搜索。具体用法为:关键词+空格+20xx年+两个英文句号+20xx年。
实例,人工智能2018..2020表示搜索2018年至2020年关于人工智能领域的资讯分析或者行业报告。
# intitle:限定搜索标题中包含的关键词
为了避免搜到许多零零散散相关度很低的内容,我们会使用intitle来提高搜索效率。当使用intitle指令时,在搜索返回的搜索结果中,网页标题栏要包含关键词,它的具体用法是:关键词+空格+intitle+英文冒号+需要限定的关键词。
实例,intitle:指数报告表示查找网址title中包含“指数报告”的网页。
# inurl:限定搜索结果的网址中包含的字段
inurl这个指令用于搜索关键词出现在URL中的页面,可以按英文字面意思理解。具体用法为:关键词+空格+inurl:xxx(xxx可以为任意字符串),此命令是查找URL中包含xxx的网页。
实例,小黑瓶 inurl:lancome表示在搜索的网址里,一定要有lancome字段,这样能直接定位到兰蔻的官网。
# “-”减号的运用:搜索信息中不包含某些词
这个指令可以用来减掉一些自己不看的信息和网站。具体用法为:搜索关键词+“-”+需要删除的关键词1+“-”+需要删除的关键词2,此命令可以删除掉部分不相关的关键词。
实例,注册会计师-广告-推广,搜索关键词“注册会计师”,并去掉广告和推广链接。
上述6种技巧的总结如下:

# 笔记记录方法
# 康奈尔笔记法
康奈尔笔记法,是一种适用于记录、阅读、复习、记忆,符合传统笔记使用场景的笔记方法。

康奈尔笔记把笔记本上的一页纸,用倒T格式分成了三部分,右上角部分划分出来的最大一块区域是笔记的主体部分,即主栏,用来记录听讲或者阅读过程中需要记录的关键信息;左边细长条的副栏是思考部分。顾名思义,这部分空间留出来,是为了将自己课后或者阅读之后的想法、问题、意见和体会之类的总结写下来;底下是记忆栏,主要用来在下课后尽早地将课程内容、概念等简明扼要地概括,并且编制成提纲、摘要或者策略。
康奈尔笔记结构包含了非常高效科学的学习流程,即重点记录、自主思考、及时总结、高效复习。
# 麦肯锡空雨伞笔记法
空雨伞笔记法是一种高效思考模型,适用于工作的场合,也就是需要快速决策的场景。放在笔记场景里就是,你了解到哪些信息?根据这些信息,你对事情的发展有什么判断?基于这些判断,你可以采取什么行动?
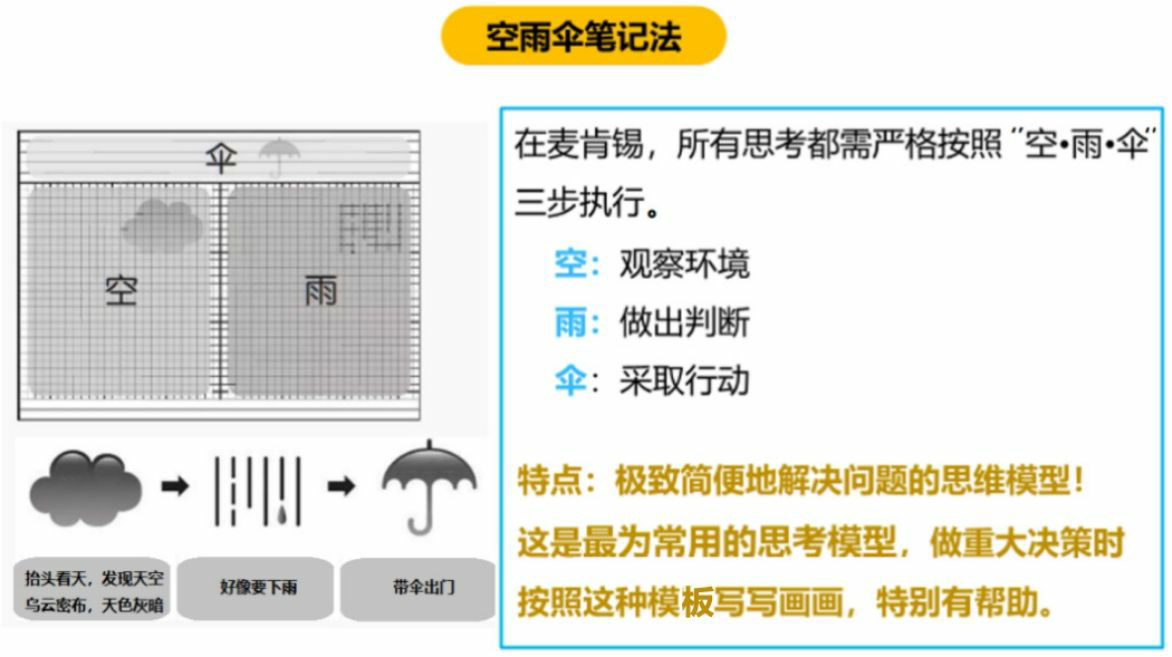
实例,当看到了关于深圳市近十年停止城中村改造拆迁的政府规划,在阅读的过程中,就可以把要点总结在空的部分,然后根据政策做出一个粗略的判断,比如,预判房价短期不会再暴涨。最后就是思考行动方向,也就是填写伞的部分,即自己应该怎么做。
# 便签条笔记
我们在阅读的同时,就可以对书的内容进行总结和思考。把要点和启发在便签条上记下来,贴在书的旁边,如果用ipad看电子书,可以采用liquidText进行操作。
种阅读方法的好处是,一个步骤实现了边阅读边吸收的效果。同时,插入的便签条可以不用翻开书,便能快速地定位书的内容,而且便签条容易撕掉、转移和组合,当我们多次阅读的时候,产生了新的想法和理解,还可以进行及时的更新。
# 提高github访问速度
# 修改Hosts和DNS提高访问速度
Hosts文件所在位置为C:\Windows\System32\drivers\etc,文件名为hosts,没有扩展名。
在hosts文件中追加两行:
140.82.113.4 github.com
199.232.69.194 github.global.ssl.fastly.net
其中,github.com的地址在github.com.ipaddress.com (opens new window)上查找;github.global.ssl.fastly.net的地址在fastly.net.ipaddress.com/github.global.ssl.fastly.net (opens new window)上查找。
刷新DNS:在CMD环境中执行ipconfig /flushdns即可清除DNS缓存内容。
另外,查看DNS缓存内容的命令是ipconfig /displaydns。

# 使用工具“边车”提高github访问速度
开发者边车 (opens new window),命名取自service-mesh的service-sidecar,意为为开发者打辅助的边车工具,通过本地代理的方式将https请求代理到一些国内的加速通道上
这是目前发现最稳定的访问github方法,到边车的gitee下载页面 (opens new window),下载之后安装,如下图所示。

在“默认模式”下,基本上github就都能正常访问了,不过需要根据指引一步一步安装证书,其原理还是通过代理实现的。
# 在线语音转文字
推荐1: 网易见外 (opens new window),免费使用,在页面选择新建项目时,能看到它提供的8大功能,如下所示。

推荐2: i笛云听写 (opens new window),每天每个人有10个小时的语音转文字时间,基本上够用了,文字识别也比较准确,使用界面如下所示。

# 文件二维码传输最佳实践
使用新版本的QR_file_transtor软件,使用时先用node app.js s [待转换文件],将文件转换为二维码,看看有多少张图片,假设是。
然后用手机打开quickEdit,新建文本之后,不断按回车到个空行。
然后打开百度输入法,把手机断网,然后打开相机app,进入扫码模式,扫描之后点复制,然后不粘贴直接换下张图片,再扫描再复制,不好复制的就跳过。
将所有跳过的二维码,再用支付宝的二维码进行扫描,能够复制。
最后进quickEdit,弹出百度输入法之后,点击剪贴板,然后每行粘贴即可。
# 电脑扫描手机生成的二维码传输文字
手机使用“一个木函” (opens new window)生成大段文字的二维码,在手机上进行展示。
电脑端使用python运行下面代码,需要提前安装好相应依赖,pip install pyzbar opencv-python pyperclip,其中pyzbar是二维码识别库,opencv调用电脑摄像头获取图片,pyperclip将识别的二维码复制到剪贴板。
# coding: utf-8
import cv2
import pyperclip
from pyzbar import pyzbar
from time import sleep
# 实例化摄像头
capture = cv2.VideoCapture(0)
data = ""
while 1:
# 首先我们要用刚才实例化的摄像头来采集实时的照片,
ret, frame = capture.read()
# 然后用pyzbar的函数来解析图片里面是否有二维码
qr_info_list = pyzbar.decode(frame)
# qr获得一个list
if qr_info_list:
for qr_info in qr_info_list:
# 对list中的每一项进行解码
data = qr_info.data.decode('utf-8')
print("识别到的二维码为:\n{0}".format(data))
try:
# 将解码后的文字存入剪贴板
pyperclip.copy(data)
except Exception as e:
print("出现错误")
# 降低计算机资源消耗,每隔70ms显示一次
sleep(0.07)
# 显示摄像头图像
cv2.imshow('camera', frame)
# 按q退出
if cv2.waitKey(1) == ord('q') or len(data) > 2:
break
# 一切完成后,释放资源
capture.release()
cv2.destroyAllWindows()
# 安卓手机推荐小众软件
Markor:用于手机连接键盘时编辑markdown文件。
坚果云markdown:适合手机端编辑markdown文件,能够预览Latex公式。
百度输入法:在连接外接键盘时比较给力,同时剪贴板的内存够大,能够方便的转换二维码。
Termux:手机运行git、node、python代码必备
Remote Desktop:微软出品,用于远程连接。
QuickEdit:手机端文本编辑器。
MX player pro:本地播放器。
DeoVR Card:查看VR视频
pinbox:跨平台收藏
# 论文写作资源搜索
# 论文下载
2021年8月可用的账号如下所示:
| 学校 | 账户 | password | 数据库地址 |
|---|---|---|---|
| 信工大 | 休闲广场大学1~200 | xxgcdxtsg | https://www.cnki.net/ |
| 国大军文 | 精神文化效益01~10 | jswhxy01~10 | https://www.cnki.net/ |
| 陆工大 | 路径过程对象001~120 | cnki001~120 | https://www.cnki.net/ |
| 国大军文 | DX2029 | 官方介绍武汉 | https://www.cnki.net/ |
| 空工大 | 科技广场对象01~10 | 科技广场对象01~10 | https://www.cnki.net/ |
# 知网期刊批量下载
以《软件学报》 (opens new window)为例,在chrome浏览器中打开地址,用户名密码登录后,按F12打开控制台,然后在控制台中输入下列代码:
// 获取所有文章链接
const aList = $('#CataLogContent .name a')
// 以每1秒的速度打开所有文章
for (let i = 0; i < aList.length; i++) {
const a = aList[i];
setTimeout(()=>a.click(), i*1000)
}
等文章全部打开后,用鼠标点击第一个自动打开的文章,然后点击pdf下载按钮,随后使用快捷键ctrl+W关闭当前标签,然后继续下一个页面的点击pdf下载按钮即可。
# 得到知识搜索
得到搜索 (opens new window)可以搜索电子书的全文,并且可以任意试读10%章节。
为了增加得到搜索的能力,可以在油猴脚本中增加下面代码:
// ==UserScript==
// @name 得到搜索
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://www.dedao.cn/*
// @run-at document-end
// @grant unsafeWindow
// @grant GM_setClipboard
// @require http://libs.baidu.com/jquery/2.0.0/jquery.min.js
// ==/UserScript==
(function() {
'use strict';
// 创建按钮
function create_button(text, id, background="#e33e33"){
const button = document.createElement("button"); //创建一个按钮
button.textContent = text; //按钮内容
if($(`#${id}`) )$(`#${id}`).remove(); // 如果已经有这个id的元素了,那么将其移除
button.id = id;
button.style.width = `${text.length * 20}px`; //根据按钮内容自动改变按钮宽度
button.style.height = "28px"; //按钮高度
button.style.align = "center"; //文本居中
button.style.color = "white"; //按钮文字颜色
button.style.background = background; //按钮底色
button.style.border = `1px solid ${background}`; //边框属性
button.style.borderRadius = "4px"; //按钮四个角弧度
button.style.marginLeft = "20px";
return button
}
// 给指定id的元素增加复制事件
function add_copy_event(element_id, copy_str){
$(`#${element_id}`).on("click", function (e) {
e.preventDefault(); // 阻止默认行为
e.stopPropagation(); // 阻止冒泡, 防止触发a标签事件
GM_setClipboard(copy_str)
});
}
// 获得书籍信息
function get_book_info(book){
if(!book) return ""
const book_name = book.operating_title
const book_author = book.book_author
const publish_time = book.publish_time
return `${book_author}. ${book_name}[M]. 出版社, ${publish_time}.`
}
(function() {
// 拦截页面的所有XMLHttpRequest请求
var origOpen = XMLHttpRequest.prototype.open;
XMLHttpRequest.prototype.open = function() {
this.addEventListener('load', function() {
if(this.readyState === 4 && this.responseURL.endsWith("searchebookcontent")){
console.log("开始处理")
const content = JSON.parse(this.responseText)
const page = content.c ? content.c.page : null; // 获取页码
const size = content.c ? content.c.size : null; // 获取每页大小
let previous_num = (page - 1) * size
// 获取书籍信息
const book = content.c ? content.c.book : null;
let book_str = get_book_info(book)
// 章节列表
const chapter_list = content.c ? content.c.list : null
let all_chapter_str = ""
if(chapter_list){
for (let i = 0; i < chapter_list.length; i++){
let chapter = chapter_list[i]
if(!chapter.Chapter)continue;
// 增加所有段落信息
all_chapter_str += chapter.Chapter + "========================================\n\n"
// 增加单段落信息
const chapter_btn = create_button(`复制段落${previous_num+i+1}`, `chapter-${previous_num+i}-btn`,'#5c7cfa')
$("li.list-item")[previous_num+i].appendChild(chapter_btn);
add_copy_event(`chapter-${previous_num+i}-btn`, `\n---------${book_str} 开始---------\n\n`+chapter.Chapter+`\n---------${book_str} 结束---------\n`);
}
}
const book_info_btn = create_button("复制书籍信息", "bookInfo_cp_btn")
const chapter_content_btn = create_button("复制所有段落", "allChapter_cp_btn")
$('.ebook-detail')[0].parentNode.append(book_info_btn)
$('.ebook-detail')[0].parentNode.append(chapter_content_btn)
add_copy_event("bookInfo_cp_btn", book_str);
add_copy_event("allChapter_cp_btn", all_chapter_str);
// 增加段落高度,保证内容都能显示
const para_list = $(".list-item .summary.iget-common-f4.iget-common-c1")
for(let i = 0; i < para_list.length; i++){
const content_length = para_list[i].innerHTML.length
para_list[i].style.height = `${content_length * 0.7 < 50 ? 50 : content_length * 0.7}px`
}
}
});
origOpen.apply(this, arguments);
};
})();
})();

原版得到搜索如上图所示,使用得到搜索增强的脚本时,在电子书信息搜索增加了两个功能,一是能够一键复制段落内容和书籍信息,并且内容比网址显示的更多更全面,二是扩大了网页的段落显示,效果如下所示。

# 全文翻译英文技术文档和书籍
# mobi、epub等格式的英文技术文档全文翻译
第一步,下载最新的英文技术书籍,可以到SaltTiger (opens new window)下载,也可以通过在libgen (opens new window)进行关键词搜索。
第二步,将电子书导入到Calibre (opens new window)电子书管理软件中,然后把epub或者mobi格式电子书转换为calibre自带的htmlz格式,如下图右上角所示。

第三步,将htmlz格式的电子书扩展名改为zip,然后解压,解压后的文件目录如下所示。

第四步,使用chrome浏览器打开index.html文件,能够正常阅读,然后打开chrome自带的翻译功能,此时会将当页内容翻译为中文,对于<code>标签包裹的内容,chrome浏览器会保持原样输出,翻译前如下图所示:

使用chrome浏览器翻译后的效果如下:

但是采用这种翻译只对当前页面有效,需要进一步优化。
第五步,使用js代码让页面自动滚动,按“F12”键,打开控制台标签“console”,然后在控制台输入下面代码:
let pagePos = 0;
setInterval(function(){
pagePos += 100;
scroll(0,pagePos)
}, 500)
上述代码表示每500毫秒往下滚动100像素高度,这样页面就自动开始滚动,结合chrome浏览器的自动翻译,就可以自动翻译整个页面全文。
最后使用快捷键ctrl+s保存页面。
第六步,保存页面之后,对于书签等<a>标签跳转链接,可能使用的源文件路径,此时需要形如file://xxx的开头部分删除掉,只留下hash路径,即形如#calibre部分,这样就能自动跳转。通常可以使用vscode的替换功能全文搜索替换。
# pdf格式的英文文档全文翻译
在兰德 (opens new window)官网下载英文报告一般为pdf格式,怎么样较好的进行全文翻译呢?
首先,将下载的pdf文档转换成为html文件,使用pdfelement即可,点击转换标签页,选择转换为html按钮,如下图所示。

然后对转换后的html文件进行处理,去除掉不必要的换行符,一般在vscode中进行操作,主要有如下操作
- 将
-</br>删除 - 将
</br>替换为空格 - 将所有的两个空格替换为一个空格
然后就可以按照之前的方法,使用chrome进行翻译了。
提示
可以使用彩云小译 (opens new window)的chrome插件,实现中英文对照翻译效果
# 英文pdf使用有道文档翻译(网易翻译)
进入有道文档翻译 (opens new window),登录后上传pdf文件(不得大于10MB)。
为了能够自动滚动页面和批量下载图片,需要在油猴脚本(Tampermonkey)中加载脚本,脚本全文如下:
// ==UserScript==
// @name 有道文档翻译图片下载
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author You
// @match https://pdf.youdao.com/docview.html*
// @grant GM_openInTab
// @require http://libs.baidu.com/jquery/2.0.0/jquery.min.js
// ==/UserScript==
(function() {
'use strict';
// 创建按钮
function create_button(text, id, background="#e33e33"){
const button = document.createElement("button"); //创建一个按钮
button.textContent = text; //按钮内容
if($(`#${id}`) )$(`#${id}`).remove(); // 如果已经有这个id的元素了,那么将其移除
button.id = id;
button.style.width = `${text.length * 20}px`; //根据按钮内容自动改变按钮宽度
button.style.height = "28px"; //按钮高度
button.style.align = "center"; //文本居中
button.style.color = "white"; //按钮文字颜色
button.style.background = background; //按钮底色
button.style.border = `1px solid ${background}`; //边框属性
button.style.borderRadius = "4px"; //按钮四个角弧度
button.style.marginLeft = "20px";
return button
}
// 下载图片的功能
function download_imgs(){
const trans_elements = $("#docTranslationImg .doc-img-wrapper img")
console.log(`共需要下载${trans_elements.length}张图片`)
for(let i = 0; i < trans_elements.length; i++){
const img_ele = trans_elements[i];
let img_url = img_ele.dataset?img_ele.dataset.src:img_ele.src // 获得url
// 间隔0.8秒下载下一张图片
setTimeout(function(){
GM_openInTab(img_url)
}, i*800)
}
}
// 是否滚动到页面底部
function is_scroll_bottom(){
// const $ele = $(`#${element_id}`)
// const sum_height = $ele.prop('scrollHeight') // 总高度
// const current_height = $ele.scrollTop() // 当前滚动高度
// // 如果差距小于500,说明已经到页面底部了
// if(sum_height-current_height < 500 ) return true
// return false
// 改为通过判断是否出现正在翻译的提示来判断
return $("#loaderProgress").css("display") === 'block'
}
// 判断是否到达文档末尾
function is_end(){
return $("#payContainer").css("display") === 'block'
}
var is_auto_scroll = false
var pagePos = 0;
// 自动滚动功能
function auto_scroll(){
// 自动滚动,使用setTimeout递归调用
function _auto(){
// 到达文档末尾则停止滚动并自动下载图片
console.log(is_end())
if(is_end()){
is_auto_scroll = false
download_imgs()
}
// 如果没有到达底部,则位置继续向下
if(!is_scroll_bottom())pagePos += 370;
document.getElementById("docTranslationImg").scroll(0,pagePos)
if(is_auto_scroll){
setTimeout(_auto, 250)
}
}
_auto(); // 调用函数
}
function start_or_pause_scroll(){
if(is_auto_scroll){
is_auto_scroll=false;
}else{
is_auto_scroll = true
auto_scroll()
}
}
// 创建下载译文图片按钮
const download_all_btn = create_button("下载图片", "download_all_btn")
$("#docTranslation div")[0].append(download_all_btn)
$("#download_all_btn").on("click", function (e) {
e.preventDefault(); // 阻止默认行为
e.stopPropagation(); // 阻止冒泡, 防止触发a标签事件
download_imgs()
});
const auto_scroll_btn = create_button("开始/暂停滚动", "auto_scroll_btn", "#74b816")
$("#docTranslation div")[0].append(auto_scroll_btn)
$("#auto_scroll_btn").on("click", function (e) {
e.preventDefault(); // 阻止默认行为
e.stopPropagation(); // 阻止冒泡, 防止触发a标签事件
start_or_pause_scroll()
});
})();
将上面的代码复制到油猴脚本中保存即可,以后再批量下载图片就可以直接使用了。
加载完成后,刷新有道文档翻译界面,会在译文区增加两个按钮功能,如下图所示:

其中开始/暂停滚动是让页面自动滚动,每次滚动到末尾时,有道会加载新页面,所以需要不停下滚,为了能触发自动加载新页面,需要把鼠标放到译文区,下载图片则是以tran-页码.jpg的形式,将所有已经下载或的页面全部下载下来。
为了方便操作,点击开始/暂停滚动之后,如果滚动到文档末尾,会自动触发下载图片功能,方便获取全文。
使用该方法得到的图片如下所示,可以再使用“acrobat”或者“pdfelement”将其合并成一个pdf,然后使用“abbyy”进行文字识别。

# 删除有道文档翻译下载的所有翻译图片并生成pdf合集
使用python的img2pdf模块,首先pip install img2pdf安装模块,然后新建python文件后输入下面代码:
import os
import time
from PIL import Image
import img2pdf
# 图片文件目录
DOWNLOAD_PATH = r"E:\Downloads"
# 合并成功后是否删除文件
IS_DELETE_FILE = True
# 是否压缩文件
IS_COMPRESS = True
# 压缩图片质量,默认为80
IMG_QUALITY = 80
def compress_img(jpg_list):
"""
压缩jpg文件
:param jpg_list: 图片文件位置列表
:return:
"""
for jpg_path in jpg_list:
# 使用pillow库打开文件并压缩
with Image.open(jpg_path) as im:
im.save(jpg_path + ".jpg", quality=IMG_QUALITY)
os.remove(jpg_path) # 删除压缩前的原文件
# 将压缩后的文件保存为压缩前的名字
os.rename(jpg_path + ".jpg", jpg_path)
def from_photo_to_pdf(jpg_list):
"""
将图片文件地址的列表合并成一个pdf文件
:param jpg_list: 图片文件位置列表,例如["E:\Downloads\tran-0.jpeg','E:\Downloads\tran-1.jpeg]
:return:合并的pdf文件位置
"""
# 按照A4大小自定义pdf文件的单页的宽和高
a4 = (img2pdf.mm_to_pt(720), img2pdf.mm_to_pt(1080))
layout_fun = img2pdf.get_layout_fun(a4)
time_now = time.strftime('%Y%m%d_%H%M%S',time.localtime(time.time()))
pdf = os.path.join(DOWNLOAD_PATH, "转换_%s.pdf" %(time_now,))
with open(pdf, 'wb') as f:
f.write(img2pdf.convert(jpg_list, layout_fun=layout_fun))
return pdf
jpg_list = []
page_i = 0
# 获取所有的翻译后的jpeg文件,由于翻译后的文件是按照tran-0.jpeg, tran-1.jpeg排序的,因此进行遍历
while True:
jpg_file = os.path.join(DOWNLOAD_PATH, "tran-%s.jpeg" % (page_i,))
if not os.path.exists(jpg_file):
break
# 重复图片文件处理,有时候会出现多下载了一次文件的情况,此时文件夹会出现两张相同照片
# 例如“tran-91.jpeg”和“tran-91 (1).jpeg”,如果相同则删除重复文件
duplication_file = os.path.join(DOWNLOAD_PATH, "tran-%s (1).jpeg" % (page_i,))
if os.path.exists(duplication_file) and os.path.getsize(duplication_file) == os.path.getsize(jpg_file):
os.remove(duplication_file)
jpg_list.append(jpg_file)
page_i += 1
# 合并pdf文件,当图片列表大于零才新生成pdf
if len(jpg_list) == 0:
raise RuntimeError("文件夹[%s]中没有指定图片" % DOWNLOAD_PATH)
# 压缩文件
if IS_COMPRESS:
print("正在压缩%s张图片" % len(jpg_list))
compress_img(jpg_list)
# 获得合并后的pdf
merged_pdf = from_photo_to_pdf(jpg_list)
# 如果允许删除源文件,同时生成的pdf存在且大于100KB,则删除源图片文件
if IS_DELETE_FILE and os.path.exists(merged_pdf) and os.path.getsize(merged_pdf) > 100*1024:
for jpg in jpg_list:
os.remove(jpg)
print("一共合并%s张图片,pdf文件位于%s,运行结束" % (len(jpg_list),merged_pdf))
其中,DOWNLOAD_PATH是下载的图片文件目录,需要根据情况进行指定,我本机位置是E:\Downloads,最后的输出结果像这样:一共合并98张图片,pdf文件位于E:\Downloads\转换_20210829_003206.pdf,运行结束。
# 国际军事刊物获取途径
# 美国国防部(www.defense.gov)
可以正常访问,比较常用的链接是美国国防部信息发布 (opens new window),人工智能报告 (opens new window)等,网站图片很分辨率较高。

# 美国传统基金会(www.heritage.org)
无法正常访问,常用链接有军力报告 (opens new window),可惜无法直接访问。
折中的办法是使用能够直联访问的google镜像输入搜索关键词:site:https://www.heritage.org/asia/report/ china,即搜索所有带有China的报告,然后点击网页快照查看,如果想查看pdf文件,则搜索site:heritage.org filetype:pdf china,能够搜索到所有带有China的pdf文件。
美国传统基金会的报告下载地址通常是:www.heritage.org/sites/default/files/2020-02/SR221.pdf(截止2021年5月底),不过直接访问是无法下载的,所以只能依托网页快照进行查看。
# 兰德公司(www.rand.org)
可以直接访问,比较常用的链接有兰德公司研究报告 (opens new window)。
# 美国战略与预算评估中心(csbaonline.org)
可以直接访问,美国战略与预算评估中心简称CSBA(Center for Strategic and Budgetary Assessments),主要的资源可以在研究出版物 (opens new window)下载,研究领域有四个,分别是战略与政策 (opens new window),预算与资源 (opens new window),未来战争与概念 (opens new window)和力量与能力 (opens new window)。
# 美国国防部高级研究计划局(darpa.mil)
无法正常访问,美国国防部高级研究计划局简称DARPA(Defense Advanced Research Projects Agency),同样可以采用google镜像搜索,然后点击网页快照的方式浏览感兴趣的内容。示例如下:搜索所有跟人工智能相关的页面的关键词为site:www.darpa.mil intelligence,搜索所有的pdf文档关键词为site:www.darpa.mil filetype:pdf。
# 新美国安全中心(www.cnas.org)
可以正常访问,比较常用的链接是下一代国防战略 (opens new window),人工智能与全球安全 (opens new window),中国挑战 (opens new window)等,具体可以看他的研究条目。
值得注意的是,他的研究内容的形式比较多样,既有传统的报告,也有新闻、博客、视频等。

# 知远防务(www.knowfar.org.cn/)
知远防务 (opens new window)是国内公开翻译外军情况的机构,能够免费查看部分资料。